
The objective is to stall the success of “zero-day” phishing sites – new sites that established controls are not yet aware of.
This proposition takes a bit for granted so consider it conceptual at best.
This is a typical PayPal phishing site:

I am operating on a theory that phishing scammers are generally lazy. I would offer that in most cases, scammers harvest the assets of legitimate sites without performing any further manipulation of those assets; it is a cut-and-paste operation.
For example, take the PayPal logo shown above:
![]()
Analyzing the XMP metadata using imageforensic.org yields the following:
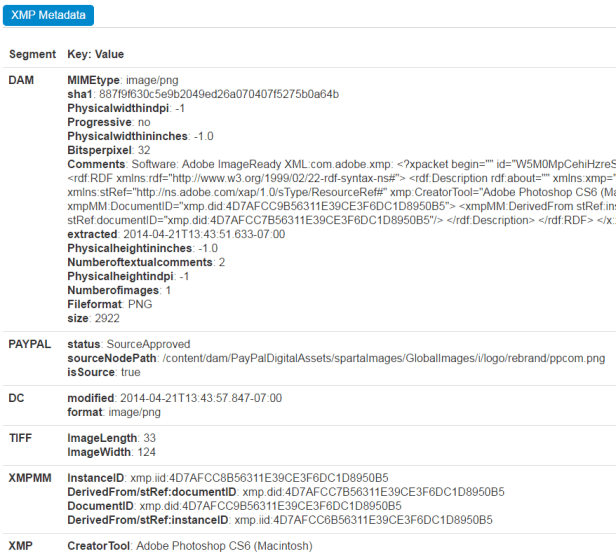
There is a lot of information here. Probably too much information to be honest. But the point I’m driving toward is:
Preconditions
- Web developers place standard XMP metadata in their collateral. For example, PayPal generates an XMP element with a value of https://paypal.com.
- Browser can read and process XMP metadata prior to presentation in the viewport
Scenario
- Browser loads malware site
- Browser interrogates the XMP metadata of assets loaded
- Browser identifies mismatch between the URL and the XMP element containing https://paypal.com
- Site is made inaccessible to the user and reported
In some sense this is performing a kind of very hacky digital signature check on the asset.
Image hashes could be evaluated but would require a higher level of coordination with some kind of hash database.
In this example above, as long as a developer and a browser agree on a standard name/value pair, the validation is self-contained and requires no additional resources (at least at pageload).
The shelf life of this solution may be short, as scammers discover they’ll have to doctor up XMP metadata to pass this kind of phishing validation.
Ideally the implementation could be creative enough to make it difficult, slow the lifecycle down, give established anti-phishing controls (endpoint, DNS) more time to become aware of new sites.
-cp
